The internet is a very volatile place. Content and information appears and disappears at a very short time. I've thought about it lately because I used Pocket since 2013 and Wallabag for about a year. When I went back and revisited all the content I saved throughout the years, most of them were unavailable. They all simply exist in my flimsy tablet with a 32GB SD Card and nowhere else. It was quite a shame since a lot of those are articles that would have been an interesting read even years from now.
That is why I encourage everyone to keep copies of interesting content you see on the internet whenever you can. Content that helped you learn a certain thing, made you laugh at one point or had a profound effect on you when you saw it, save it all. Storage is cheap and is getting cheaper through the years. Once these articles, videos and other media on the internet are gone, they are gone for good (unless someone was thoughtful enough to put in on archive.org or mirror it somewhere else but most of the time that would be the last thing on their mind).
Content on the internet will always disappear, it is only a matter of when.
Personally, I also consider saving stuff from the internet similar to making a little time capsule that would be a treat to get into a decade or so from now.
Recently, I discovered this new software called ArchiveBox. This one is written in Python and uses multiple software to archive content on the internet. For instance, it uses Chromium to get the PDF version and a screenshot of the website and wget to download the files required to load the webpage locally.
It supports Pocket and Wallabag among a plethora of services and text formats. It doesn't just save websites, it saves videos (it uses youtube-dl to do this), audio files and Git repos. Being able to archive Git repos is a feature I didn't know I needed until now actually. I tried it and it works pretty well. Although, I am not so sure yet how well it fares on active projects that update very frequently.
Now do note that ArchiveBox is still pretty early in development so not all sites you throw at it will play well with it. For example, Medium articles suddenly redirect to a 404 page when you open it through a local archive. It's strange and I don't know if it's an issue with ArchiveBox or Medium implemented shady DRM somewhere in their Javascript code.
Setting it up is pretty easy and it is detailed really well in the project's Github page.
Here's a little sneak peek of what you can expect when you get it all working.
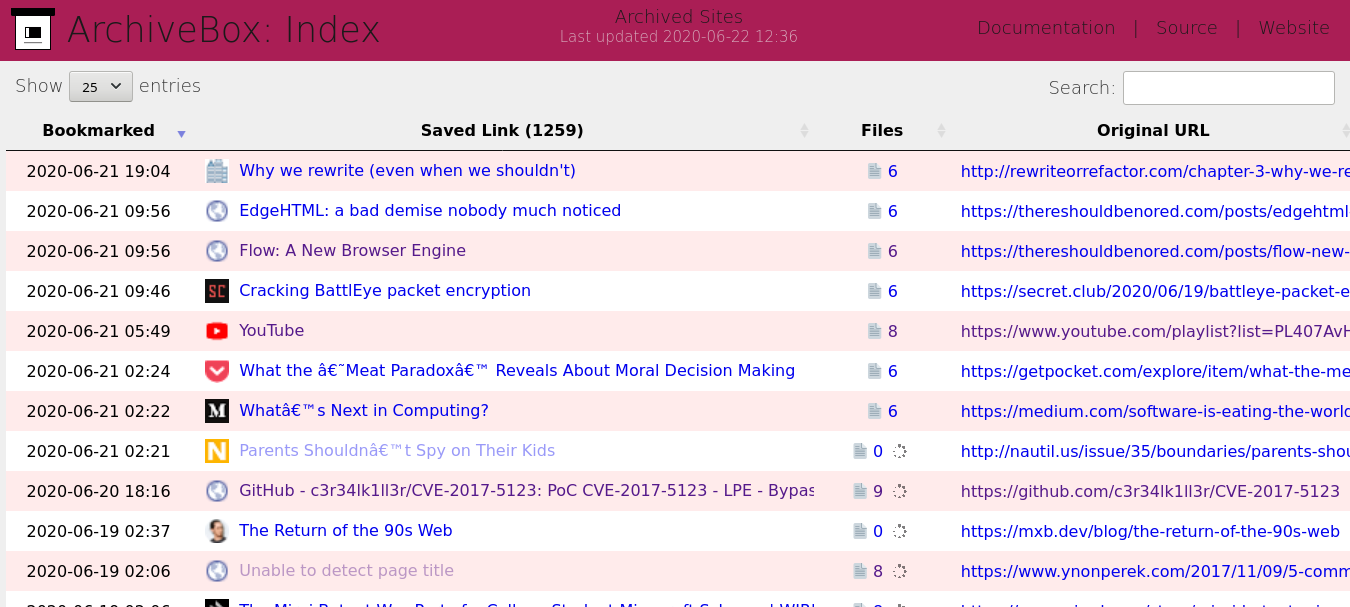
This one is the menu where you can see all the pages you have saved.
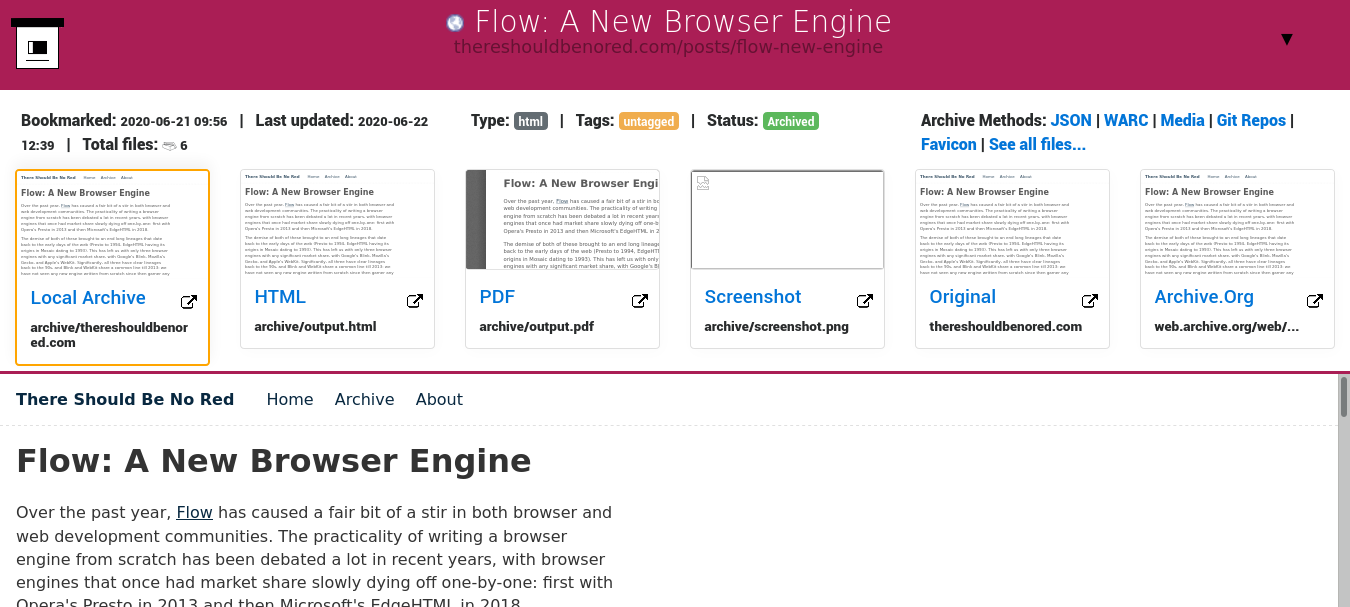
This is the page viewer. As you can see here, it's pretty thorough with its archiving.